NOTE: I will write a detailed article on chat service design in the near future and share it on systemdesign.one website.
As of now, I am sharing a brief hypothetical design of the chat service. I am open to any feedback and questions, thank you.
Chat Service
The popular implementations of the chat service are the following:
- Whatsapp
- Facebook Messenger
- Slack
- Discord
- Telegram
Requirements
- The user (sender) can start a one-to-one chat conversation with another user (receiver)
- The sender can see an acknowledgment signal for receive and read
- The user can see the online status (presence) of other users
- The user can start a group chat with other users
- The user can share media (images) files with other users
Data storage
Database schema
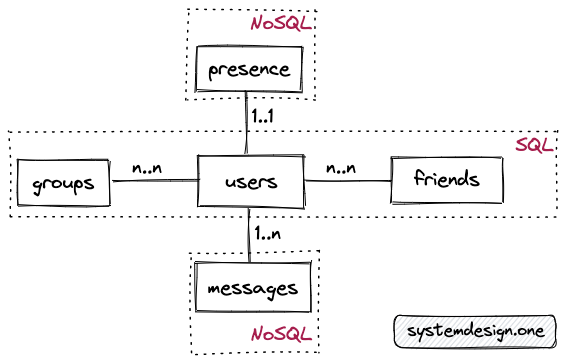
- The primary entities are the groups, the presence, the users, the friends, and the messages tables
- The relationship between the groups and users tables is many-to-many
- The relationship between the users and friends table is many-to-many
- The relationship between the users and the messages table is 1-to-many
- The relationship between the users and the presence table is 1-to-1
- The friends table is the join table to show the relationship between users
Type of data store
- SQL database such as Postgres persists the metadata (groups, avatar, friends, WebSocket URL) for ACID compliance
- NoSQL data store (LSM tree-based) such as Cassandra is used to store the chat messages
- An object store such as AWS S3 is used to store media files (images) included in the chat conversation
- A cache server such as Redis is used to store the transient data (presence status and group chat messages) to improve latency
- The publish-subscribe server is implemented using a message queue such as Apache Kafka
- The message queue stores the messages for asynchronous processing (generation of chat conversation search index)
- Lucene-based inverted index data store such as Apache Solr is used to store chat conversation search index to provide search functionality
High-level design
- The user creates an HTTP connection for authentication and fetching of the relevant metadata
- The WebSocket connection is used for real-time bidirectional chat conversations between the users
- The set data type by Redis provides constant time complexity for tracking the online presence of the users
- The object store persists the media files shared by the user on the chat conversation
Workflow
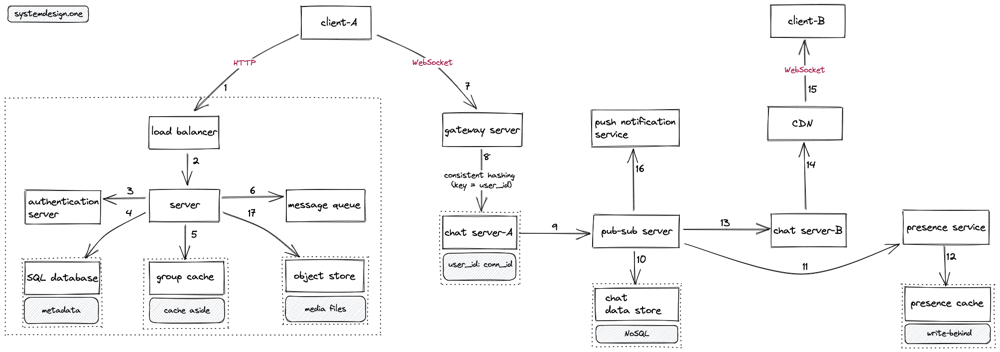
- The client creates an HTTP connection to the load balancer
- The load balancer delegates the HTTP request of the client to a server with free capacity
- The server queries the authentication service for the authentication of the client
- The server queries the SQL database to fetch the metadata such as the user groups, avatar, friends, WebSocket URL
- The server queries the group cache to fetch the group chat messages
- The server updates the message queue with asynchronous tasks such as the generation of the chat search index
- The client creates a WebSocket connection to the gateway server for real-time bidirectional chat conversations
- Consistent hashing (key = user_id) is used to delegate the WebSocket connection to the relevant chat server
- The chat server delegates the WebSocket connection to the pub-sub server to identify the chat server of the receiver
- The pub-sub server persists the chat messages on the chat data store for durability
- The pub-sub server queries the presence service to update the presence status of the user
- The presence service stores the presence status of the user on the presence cache
- The pub-sub server delegates the WebSocket connection to the chat server of the receiver
- The chat server relays the WebSocket connection through the CDN for group chat conversations
- The CDN delegates the (group) chat message to the receiver
- The pub-sub server invokes the push notification service to notify the offline clients
- The server stores the chat media files on the object store and the URL of the media file is shared with the receiver
- The admin service (not shown in the figure to reduce clutter) updates the pub-sub server with the latest routing information by querying the server
- The mapping between the user_id and WebSocket connection ID (used to identify the user WebSocket for delegation) is stored in the memory of the chat server
- The write-behind pattern is used to persist the presence cache on a key-value store
- The cache-aside pattern is used to update the group cache
- The presence cache is updated when the user connects to the chat server
- Consistent hashing (key = user_id) is used to partition the presence cache
- The offline client stores the chat message on the local storage until a WebSocket connection is established
- The background process on the receiver can retrieve messages for an improved user experience
- The clients must fetch the chat messages using pagination for improved performance
- The pub-sub server stores the chat message on the data store and forwards the chat message when the receiver is back online
- If the requirements are to keep the messages ephemeral on the server, a dedicated clean-up service is run against the replica chat data store to remove the delivered chat messages
- If the requirements are to keep the messages permanently on the server, the chat data store acts as the source of truth
- The one-to-one chat messages can be cached on the client for improved performance on future reads
- The replication factor of the chat data store must be set to at least a value of three to improve the durability
- The records in the presence cache are set with an expiry TTL of a reasonable time frame (5 minutes)
- The sliding window algorithm can be used to remove the expired records on the presence cache
- The last seen timestamp of the user is updated on the expiry of the records on the presence cache
- The stateful services are partitioned by the partition keys user_id or group_id and are replicated across data centers for high availability
- The hot shards can be handled by alerting, automatic re-partitioning of the shards, and the usage of high-end hardware
- The Apache Solr can be used to provide search functionality
- The publish-subscribe pattern is used to invoke job workers that run the search index asynchronously
- The SQL database can be configured in single-master with semi-sync replication for high availability
- The receive/read acknowledgment is updated through the WebSocket communication
- The chat messages are end-to-end encrypted using a symmetric encryption key
- The client creates a new HTTP connection on the crash of the server or the client
- The gateway server performs SSL termination of the client connection